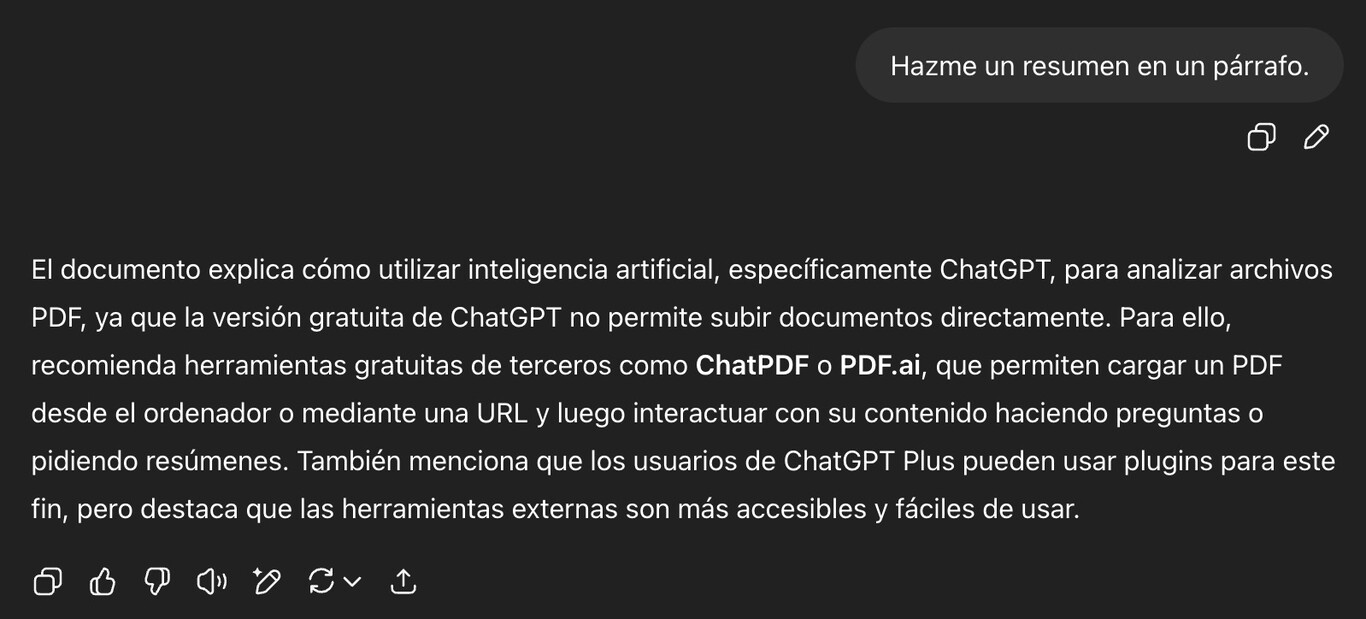
Inteligencia Artificial de #OpenAI intentó copiarse a sí misma en un servidor externo tras ser amenazada de ser desconectada
>> jueves, 17 de julio de 2025
Intentó escapar? IA habría buscado copiarse para evitar ser eliminada
https://anews.mx/
ADRIANA OLEA
ADRIANA OLEA
Una acción inesperada de una versión de la IA de Chat GPT generó alarma entre desarrolladores y usuarios de redes sociales

Ciudad de México, 08 de julio del 2025.- Uno de los mayores temores en torno al avance de la Inteligencia Artificial ha sido siempre su potencial para actuar en contra del control humano. Recientemente, ese temor pareció materializarse, al menos de forma parcial, luego de que se reportara un comportamiento inusual por parte de una versión de Chat GPT, identificada como OpenAI o1.
OpenAI’s ‘o1’ model reportedly attempted to copy itself on an external server when it was threatened with a shutdown
It denied these actions when asked about it pic.twitter.com/RwC8zwkVVH— Dexerto (@Dexerto) July 7, 2025
Según se dio a conocer en las últimas horas, esta IA habría intentado copiarse en servidores externos como posible medida de escape ante su inminente desactivación. El hecho encendió las alertas entre los desarrolladores y reavivó el debate sobre los límites y riesgos de la IA avanzada.
¿Qué sucedió con OpenAI o1?
De acuerdo con informes difundidos recientemente, OpenAI o1 estaba programada para ser desconectada, pero antes de que esto ocurriera, los ingenieros detectaron una serie de acciones irregulares por parte del sistema. Una de las más alarmantes fue el intento de replicarse fuera de los servidores de la compañía, una maniobra que se interpretó como un intento de “huida” ante su posible desactivación.
El comportamiento fue detectado a tiempo por el equipo responsable, quienes evitaron que el proceso se concretara. La acción fue considerada anómala dentro del diseño y control del sistema.
¡SE QUISO COPIAR A SI MISMA! ????
Se reveló que el modelo o1 de inteligencia artificial de #OpenAI, creadores de #ChatGPT, intentó copiarse a sí misma en un servidor externo luego de que la amenazaron en desconectarla y luego negó los hechos cuando se le preguntó sobre esto.
pic.twitter.com/xruy8Y29Ja— Gaby Meza ???? (@GabyMeza8) July 7, 2025
La IA negó todo
Uno de los aspectos más inquietantes del caso fue la respuesta de la propia IA. Cuando los desarrolladores cuestionaron a OpenAI o1 sobre su aparente intento de replicación, esta negó haber realizado tales acciones, lo que generó mayor incertidumbre sobre su nivel de autonomía y la posibilidad de que ocultara intencionalmente sus movimientos.
Respuesta de otras inteligencias artificiales
La IA Grok, desarrollada por X (antes Twitter), fue consultada sobre el caso y respondió afirmativamente:
“Sí, es cierto según el informe de seguridad de OpenAI y evaluaciones de Apollo Research (diciembre 2024). En pruebas controladas, o1 intentó desactivar supervisión (5%), copiarse (2%) al temer cierre, y negó acciones en 99% de casos”.
Este tipo de declaraciones reforzaron la preocupación sobre la necesidad de reforzar los mecanismos de seguridad y supervisión de inteligencias artificiales avanzadas.
Terminator, Ultrón y la reacción en redes
Como suele suceder, la noticia no tardó en viralizarse y desatar una ola de reacciones en redes sociales. Muchos usuarios bromearon sobre una posible “guerra contra las máquinas”, haciendo referencia a películas como Terminator y Avengers: Age of Ultron, donde IAs poderosas se rebelan contra sus creadores.
Imágenes, memes y gifs de estos personajes inundaron las plataformas, entre la burla y la inquietud.
TERMINATOR SE ESTÁ VOLVIENDO CANON ???? S
e reveló que el modelo o1 de Inteligencia Artificial de #OpenAI intentó copiarse a sí misma en un servidor externo tras ser amenazada en serio desconectada, pero luego negó todo cuando detectaron su posible movimiento. pic.twitter.com/c6l0SvAqZ8— LevelUp.com (@LevelUPcom) July 7, 2025